Dominic's Homepage!

My name is Dominic Teo and I'm currently an analytics manager with the Ministry of National Development (MND). I'm interested in the intersection of public policy and technology as well as the application of Big Data and Civic Tech in the public sphere.
I graduated Cum Laude from Sciences Po Paris with a BA in Social Sciences & Economics followed by a MS in Computational Analysis and Public Policy (MSCAPP) at the University of Chicago. The MSCAPP degree is a 2 year dual degree offered by the Schools of Computer Science and Public Policy.
Take a look at my resumé and various projects! (click on titles of projects for more details)
Hosted on GitHub Pages — Theme by orderedlist
Summarized Stats for Football Teams from FIFA 07 to FIFA 21
Project for the graduate class - Big Data Architecture and Application (MPCS 53014)
The project’s serving layer and speed layer were both deployed on the class’ AWS load balanced server but which has been discontinued. However, an overview of both layers can be seen in the below GIF.
An extensive list of all files containing code to create Hive, Hbase tables and their names as well, locations in my S3 bucket containing my web app deployment and HDFS location for jars used can be found as well as commands to deploy the speed layer can be found in the Appendix located at the end of this ReadMe.
A more detailed run-through and files used in the project can be found in my GitHub page here
Lambda Architecture
This project utilizes the famous lambda architecture that “provides comprehensive and accurate views of batch data, while simultaneously using real-time (manually added for this project) stream processing that updates batch data. There are 3 layers in this big data architecture - batch Layer which in this case will precompute average stats for each football team in the FIFA game, speed layer which will be manually created through a ‘submit-player’ form and the serving layer which stores output from the batch and speed layer and provides us with the updated average stats.
Overview & Objective of Project
Football (known in America as Soccer) is the world’s most popular sport and according to FIFA, the 2018 World Cup Final was viewed live by a combined 1.12 billion people worldwide. Football’s popularity also extends to the most popular Football video game, the FIFA series by EA Sports.
The first edition of the game began in 1994 with FIFA 95 with the latest edition being FIFA 21 which was released in 2020. Beyond improvements in the graphics, fans of football and the game continue to buy the new edition of the game every year due to changes in the stats of players and teams.
Batch Computation & Serving Layer: Because the stats of players are quite an accurate reflection of their performance in real-life and teams are comprised of players, we are able to assess if a team has improved or taken a step back in each year. We are able to do this by taking the average stats of players in each team. This would provide football fans who are able to search up their favorite teams to compare how they fare in a certain year to another year as well as compare the strength of their team relative to a rival team. Fans are able to compare specific stats of each team to see which aspect of the game they’re lacking in (Pace, Shooting, Defending, etc)
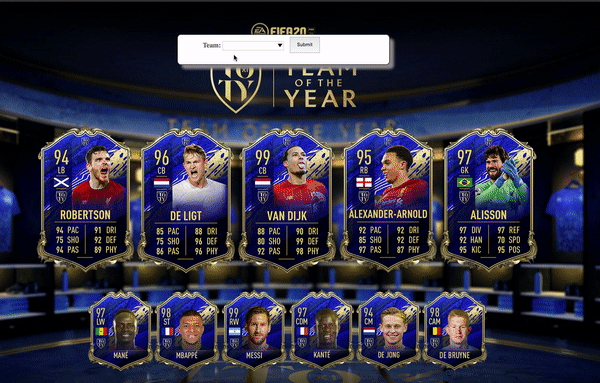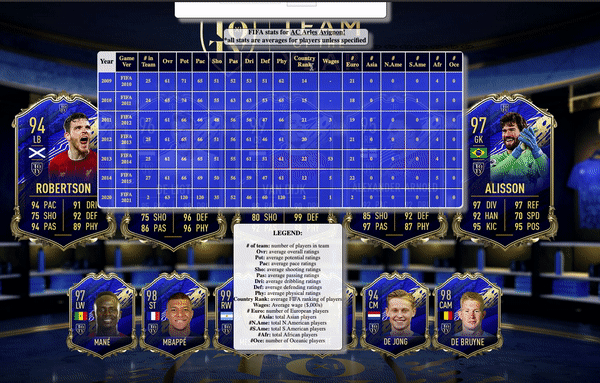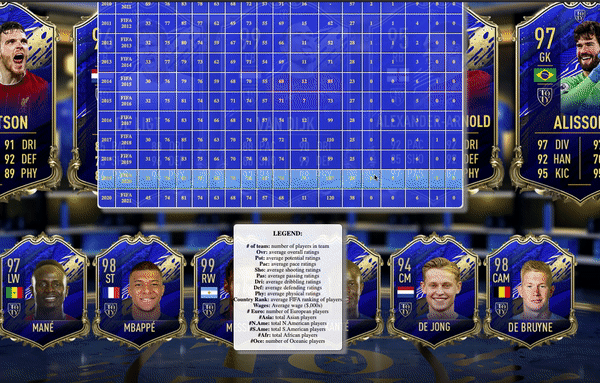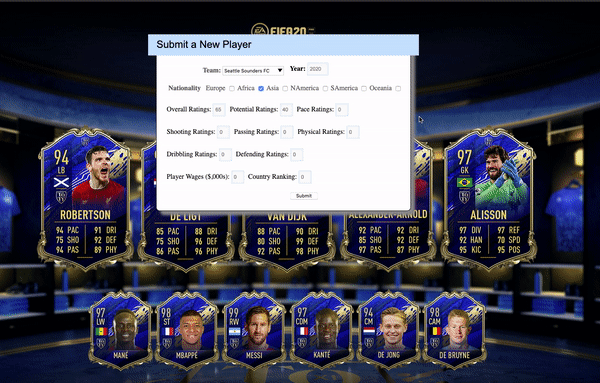
With my deployed web application, football fans are able to search for any football team that can be found in any of the editions from FIFA 07 to FIFA 21 and it will return the following stats for the selected team:
- Year
- Game Ver
- Number of Players in each Team (# in Team)
- Average Overall Ratings (Ovr)
- Average Potential Ratings (Pot)
- Average Pace Ratings (Pac)
- Average Shooting Ratings (Sho)
- Average Dribbling Ratings (Dri)
- Average Defending Ratings (Def)
- Average Physical Ratings (Phy)
- Average FIFA Country Rankings of each player’s Nationality (Country Rank)
- Average Wages (in $,000s)
- Number of European Players (# Euro)
- Number of Asian Players (# Asia)
- Number of North American Players (# N.Ame)
- Number of South American Players (# S.Ame)
- Number of African Players (# Afr)
- Number of Oceanic Players (# Oce)
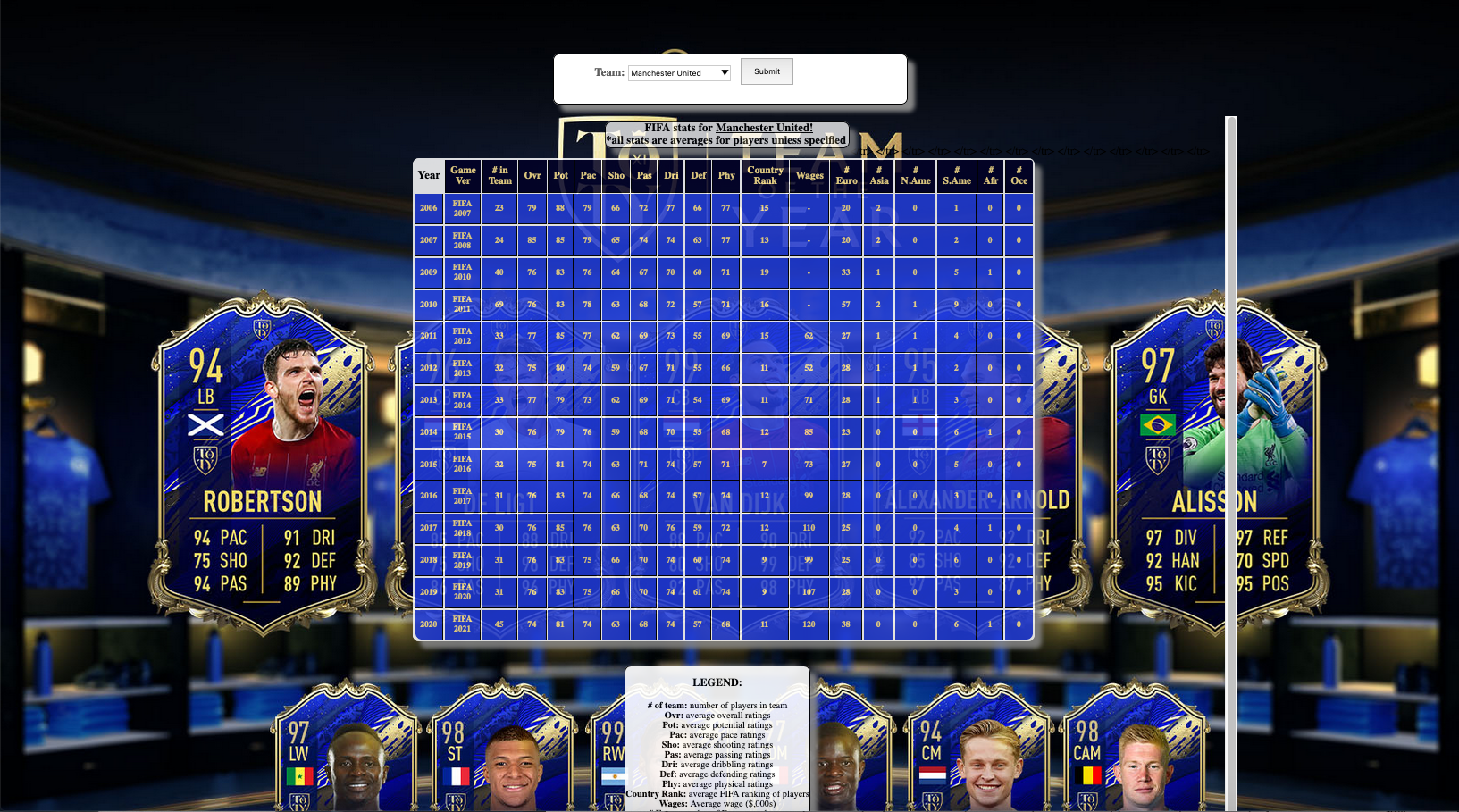
An example of choosing the football team ‘Manchester United’
Speed Layer: One exciting aspect of the FIFA video game is that it’s dynamic. Just like any other professional sport, players sometimes change teams mid-season or unknown players perform well and are sold from lower leagues (not featured in FIFA) to more prominent teams (featured in FIFA). As such I’ve created a speed layer which allows users to add players to teams that will then be reflected in the teams’ stats.
Preparation and Preprocessing
The data used in this project comes from two sources.
-
Countries data: FIFA Country Rankings from 1992 to 2020 from Kaggle. This provides the FIFA world ranking for each country as well as the continent that each country belongs to. This will be used to calculate how many European, Asian, North American etc players each team has and the average country ranking of the players for each team.
-
Players data: Stats for each player in every FIFA game from FIFA 07 (2006) to FIFA 21 (2020). Data is scrapped from the SoFIFA website. The data on players will later be grouped by team and year.
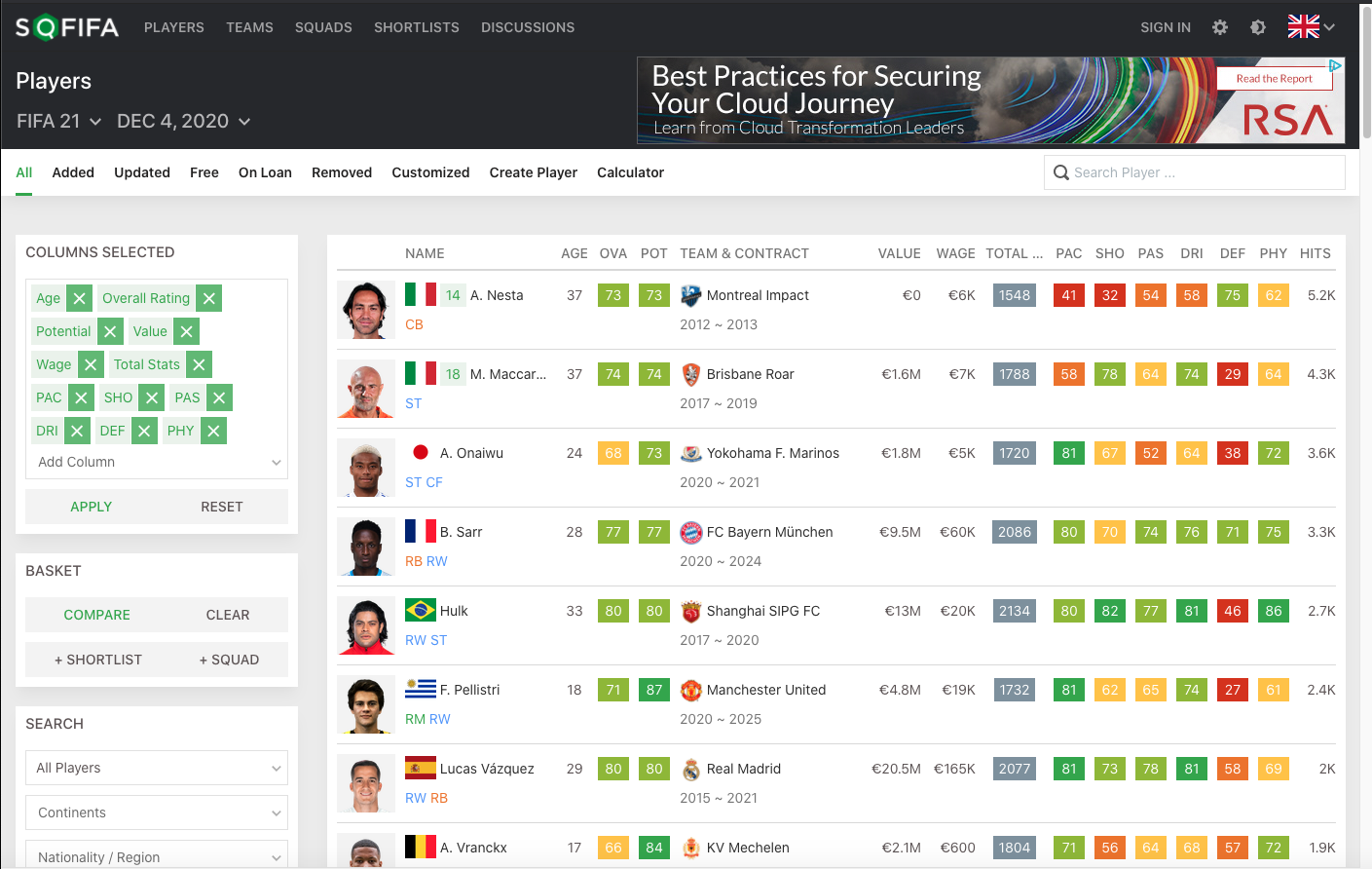
List of players and their stats on the SoFIFA website for FIFA 21
Web Scrapping from SoFIFA:
Scrapped using Python via a Jupytner Notebook and directly transferred to s3. Dataset can be found at s3://dominicteo-mpcs53014/direct_from_python/fifa_players.csv
The Jupyter Notebook used for the web-scrapping is titled FIFA-teams-players-scrapper.ipynb and uses the BeautifulSoup b. The direct transfer to my S3 bucket is based on this Medium article where I don’t have to save my scrapped CSV into my local machine, instead I write my Pandas DataFrame directly to S3 using the s3fs package.
Data from Kaggle:
Ingested into HDFS through cURL and then unzipped into S3. The code used below can also be found in the file curl-Kaggle-Fifa-country-data.sh. Dataset can be found at s3://dominicteo-mpcs53014/final_proj_country_curl/fifa_country.csv
Batch Layer
Creating Hive tables from CSVs stored in S3
After ingesting both datasets into S3, I created Hive tables based on the different CSVs that were previously ingested. The file containing the full code used for creating these Hive tables is in ingest-from-S3-Hive.hql.
Two Hive tables were created, one for the countries rankings data from Kaggle while another was for the scrapped players data.
These Hive tables were created using the OpenCSVSerde as shown below. For example, the Hive table for the countries ranking data was created using the code:
I then created empty Optimized Row Columnar (ORC) tables which I then filled with data from the Hive tables that we just created. I chose to use ORC tables as they’re a highly efficient way to store Hive data and it improves performance when Hive is reading, writing and processing data. A more extensive explanation on the numerous benefits of using a ORC table as opposed to the standard Hive table can be found here.
Players Data:
The name of the ORC table on players’ stats can be found in Hive and is called dominicteo_proj_players. I excluded the names of the football clubs that were not actually football clubs such as “” (empty string) and “111648”.
Country Data:
The name of the ORC table on countries’ stats can be found in Hive and is called dominicteo_proj_country. I also perform some minor data cleaning on the original CSV that I curled from Kaggle to ensure that this table can be joined with the players table. This includes taking only the year from the date column and creating a country_year column by concating country and year.
Combining the Data in Spark
The file for the code used to create the combined dataset can be found in sparksql-creating-combined-table.scala.
I use the spark.table() function to load the 2 ORC tables I had previously created in Hive and I’m able to join the two tables using the spark.sql() function.
However, before joining the tables, I realized that the country table can include multiple entries for the same country per year since their ranking may not stay the same across the year. I thus clean the country table first by only keeping the entry with the highest ranking for any specific country in any specific year. For example, if there are 3 entries for the United States in the year 2010 when they were 50, 55 and 60, I will only keep the entry when the US is ranked 50th.
I then am able to join the players table with the country table using as both have the column country_year which for the players contain their nationality and the year that specific FIFA game was released. For the countries, it was the name of the country and the year that the ranking came out.
I now have a table where each row represents a player in a specific FIFA game with their game statistics as well as information on the country where that player is from. However, I am not finished as what I want is not info on players but rather the teams that they belong to hence I use the Spark SQL function to create this new table that groups the players by team and the year which I then save to Hive as a Hive Table titled dominicteo_hive_proj_teams.
Important to note that while I want to serve the average statistics in my serving layer, my batch layer computes the sum of all players’ rating. This is to ensure that my table can be incremented with new data from my speed layer.
I also used Spark to create a table containing all the unique teams’ names which I will use later in my web application. I then save this into Hive as a table titled dominicteo_hive_proj_unique.
Serving Layer
My serving layer will be using Hbase tables to query data. The file containing the code for creating my Hbase tables from my Hive tables can be found in the file hbase-hive-link-with-counter.hql.
Using the Hive tables dominicteo_hive_proj_teams and dominicteo_hive_proj_unique that we created and saved to Hiveusing Spark, I created its Hbase counterpart titled dominicteo_hbase_proj_team and dominicteo_hbase_proj_unique respectively. I did this by creating it in Hive and linking it with its Hbase counterpart. This allows me to populate the new Hive table using the Spark created Hive tables and its Hbase counterpart will automatically be filled. These 2 Hbase tables will be used in my Serving layer for the web app.
The files used in the creation of the web app that was deployed can be found in my S3 bucket at s3://dominicteo-mpcs53014/final-project-load-balanced.zip The serving layer takes the Hbase tables which provides the total stats for all players in the team and calculates the averages by dividing by the number of players in each team. The code for this can be found in the app.js file that is zipped.
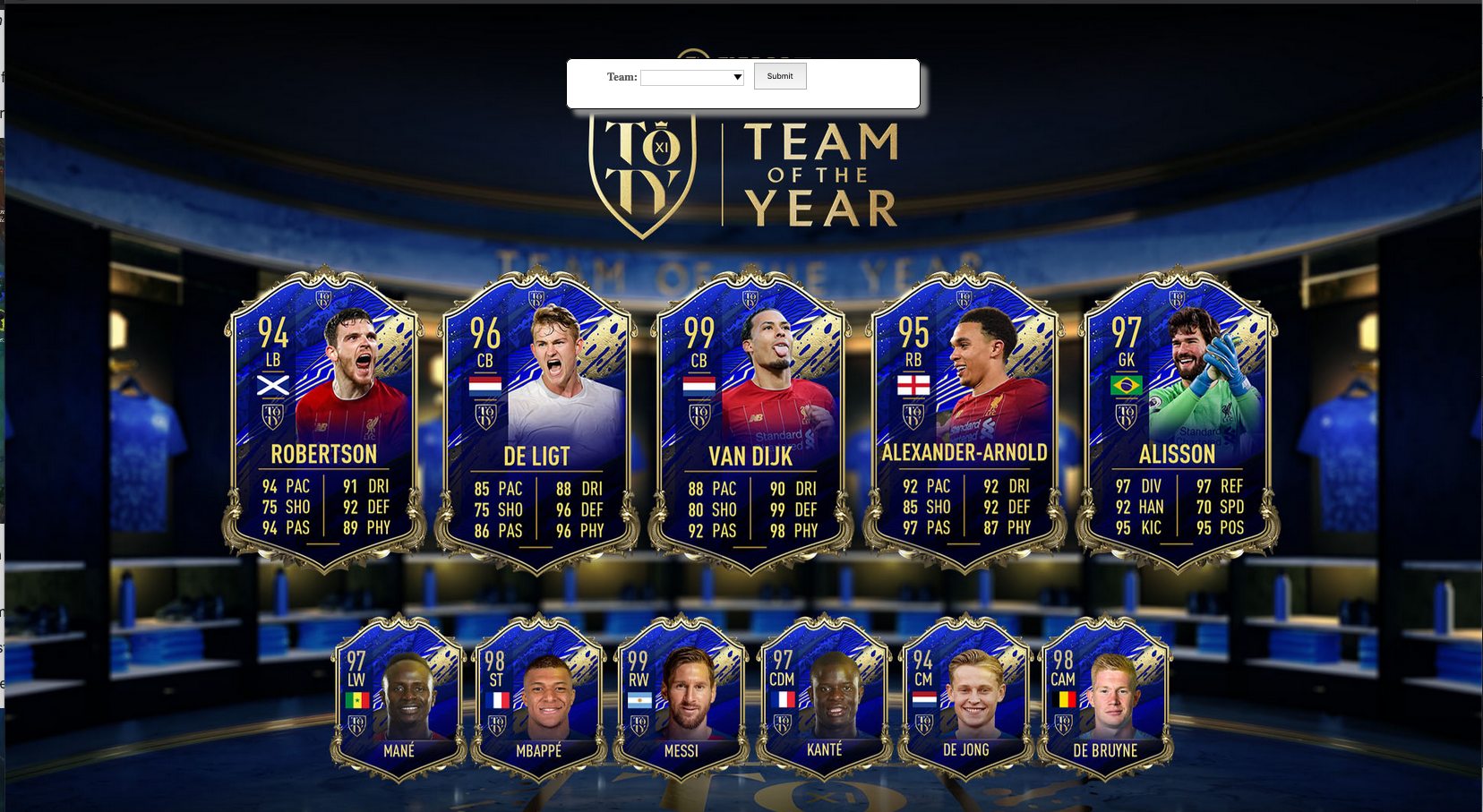
The main landing page page fifa-stats-teams.html where we are able to choose what team we’re searching for is created by the fifa-teams-unique.mustache file and can be seen below.
The results after choosing a team is created by the fifa-stats-results.mustache file. The results are displayed in a table and every row represents the teams’ stats for every year that the team appears in FIFA 07 to FIFA 21. Not every team appears in every edition of FIFA 07 to FIFA 21 as FIFA only contains teams from some leagues. Hence, if a team is relegated from that league to a lower league, it may no longer appear in that year’s edition of FIFA and vice versa if a team gets promoted from a lower league (doesn’t appear in FIFA) to a higher level league (appears in FIFA).
An example would be the team AS Béziers, a French football team that was promoted to the professional leagues in 2018.
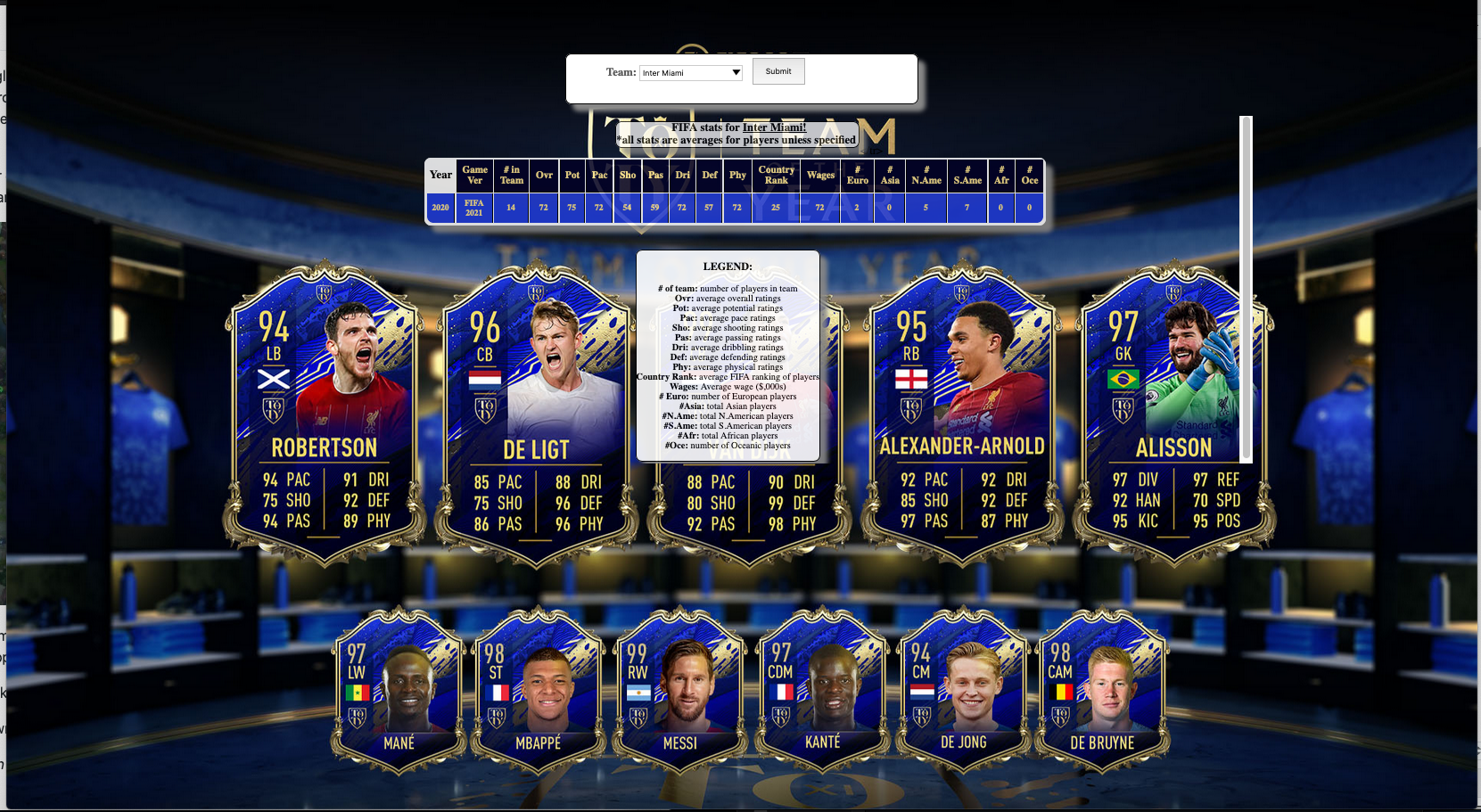
Other teams are also newly created, for example, the team Inter Miami from the American MLS league was recently created in 2020 as seen below.
Speed Layer
Since my dataset does not have real-time ingestion, I instead use a web page and Kafka message queue to increment user submitted new player data. However, before that, I need to recreate the Hbase table dominicteo_hbase_proj_team to ensure that it’s able to be incremented. The code for that can be found in the second half of the hbase-hive-link-with-counter.hql file. The difference lies in the SERDEPROPERTIES where in the mapping, at the end of each column that will be incremented, I added a #b.
The name of this Hbase table is dominicteo_hbase_proj_team_v2 and will be used in the serving layer instead of dominicteo_hbase_proj_team.
Users are able to add new players in the submit-player.html by filling in the categories shown below
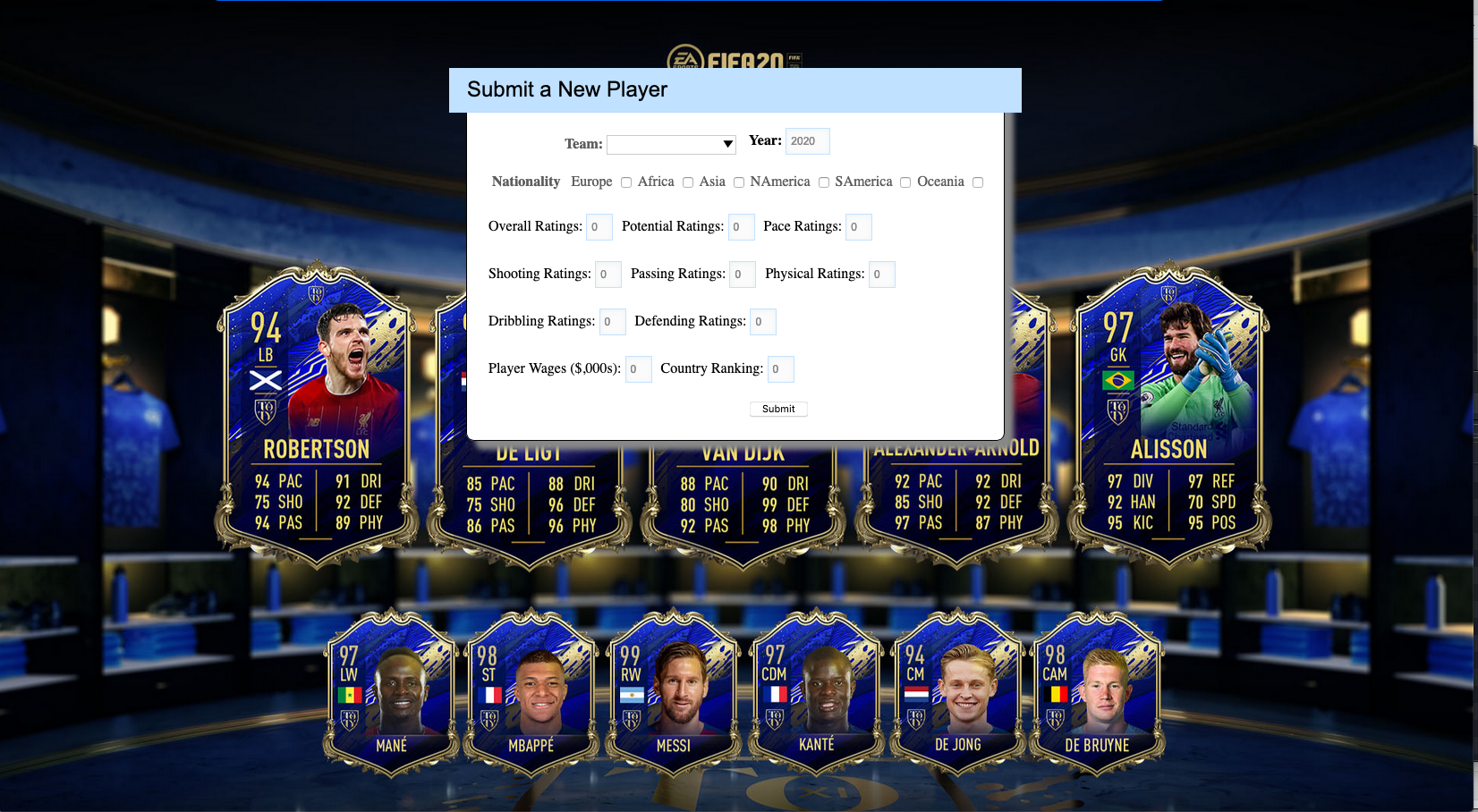
The uber jar containing the scala files which defines the KafkaPlayerRecord class and the StreamPlayers object can be found in HDFS. The uber jar is titled uber-final-proj-speed-layer-1.0-SNAPSHOT.jar and can be found at dominicteo/final-proj-speed-layer/target.
The data streaming process is written in scala and the schema of submitted players data reflects what users have to fill in :
As seen below, each time users submit the form, it is recorded in my Kafka console where I’m using the topic dominicteo-new-players-v3.

For each KafkaPlayerRecord entry to be incremented into our Hbase table dominicteo_hbase_proj_team_v2, we then have to go to our uber jar located at dominicteo/final-proj-speed-layer/target and run the following code. This code can also be found in our spark-submit-speed-layer.txt file.
Appendix
List of files being submited & locations of files and tables stored in S3, HDFS, Hive and Hbase:
-
curl-Kaggle-Fifa-country-data.sh: cURLS country data from Kaggle into S3 bucket and then unzips it into s3://dominicteo-mpcs53014/final_proj_country_curl/fifa_country.csv -
FIFA-teams-players-scrapper.ipynb: scraps players data and stats from SoFIFA.com from every edition of the FIFA video game starting from FIFA 07 to FIFA 21 using Python. Writes the Pandas DataFrame to s3://dominicteo-mpcs53014/direct_from_python/fifa_players.csv directly. -
ingest-from-S3-hive.hql: takes our CSV files from our S3 bucket and creates the relevant Hive tables as well as the respective ORC tables. 2 ORC tables are created in Hive:dominicteo_proj_countryanddominicteo_proj_players. -
sparksql-creating-combined-tables.scala: uses Spark to clean the ORC tables, combine the two and then creates the table that we want which provides stats that is aggregated by team and year. The table is then saved into Hive asdominicteo_hive_proj_teams. Also create a table containing the names of all unique values of teams and is saved into Hive asdominicteo_hive_proj_unique. -
hbase-hive-link-with-counter.hql: the first part of the file contains the code to create the respective Hbase tables from the Hive tables just created in Spark. The second half of the file contains the code that creates the Hbase table which allows for our speed layer incrementing. The name of the Hbase tables that will be used in the serving layer of our web application aredominicteo_hbase_proj_team_v2anddominicteo_hbase_proj_unique. -
kafka-commands.txt: the Kafka commands to create our Kafka topicdominicteo-new-players-v3and the command to view the entries submitted into our Kafka topic. -
spark-submit-speed-layer.txt: the command line in our Hadoop interface to utilize our uber-jar that takes entries in our Kafka topic and increments the relevant columns in our Hbase table. -
HDFS:
dominicteo/final-proj-speed-layer/targetwhich contains our Uber Jar titleduber-final-proj-speed-layer-1.0-SNAPSHOT.jar -
s3://dominicteo-mpcs53014/final-project-load-balanced.zip: the zipped file contains the files that includes ourapp.jsfile which reads our Hbase tables and computes the average stats for each team by dividing the relevant columns by the num_players column.app.jsalso sends the submited new player entry into my Kafka topicdominicteo-new-players-v3. The zipped file also contains the 3 mustache filesfifa-stats-results.mustachewhich creates the results table in our web app;fifa-teams-unique.mustachewhich creates the page that allows us to choose what team we want to select andfifa-submit-player.mustachewhich creates the form to submit new players.